全文検索したいよね。
でも、100万件とかのデータに対してRDBで「like ‘%xxxx%’」とかしたくないよね。
ということで、全文検索エンジンの登場です。
全文検索エンジンは古くからいろいろありますが、elasticsearchの特徴はその名の通りelasticにスケールアウトが簡単なとこでしょうか。
他の全文検索エンジンで有名なところだとSolrやGroongaなんかもありますが、スケールアウトの面ではelasticsearchが秀でているようです。(僕自身は他のを試したことが無いので詳細は不明ですが…)
1.まずはインストール
CentOS6.3で試しています。
elasticsearchはJavaで出来ているので、jdをインストールします。
yum install java-1.7.0-openjdk-devel
次にelasticsearchのリポジトリを追加します。
vi /etc/yum.repos.d/elasticsearch.repo
で、以下の内容をコピペ。(elasticsearch1.4.xを対象としています)
[elasticsearch-1.4] name=Elasticsearch repository for 1.4.x packages baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
んでもって、yumでインストール。
yum install elasticsearch
1つのノードだけでよければ、elasticsearchのインストールは以上で完了です。
今回は複数ノードを用意して、ドキュメントが各ノードに分散されることを確認したかったので、同じ作業を3台のサーバーに対して行いました。
(実際は勉強用の環境なので、Vagrant+Chefでサクッと3台立ち上げてprovisionしただけですが…)
で、各サーバーは以下のようになりました。
・IP:192.168.33.21(Master & Data ノード)
・IP:192.168.33.22(Data ノード)
・IP:192.168.33.23(Data ノード)
IP192.168.33.21はマスターとして各ノードを管理し、また自ノードでもデータを保持します。
それ以外はマスターに管理される状態で、データだけを保持するノードとする予定ですが、マスターやデータノードの設定は次になります。
今後の作業のために、headプラグインとkuromojiプラグインをインストールしておきます。
headプラグインはクラスターやノード、インデックスの状態を確認するためのプラグイン。なので、マスターにする192.168.33.21にのみインストールしました。
/usr/share/elasticsearch/bin/plugin -install mobz/elasticsearch-head
kuromojiは日本語の形態素解析用プラグインです。
今回の実験では使いませんが、日本語の全文検索ではほぼ必須となるでしょう。
/usr/share/elasticsearch/bin/plugin -install elasticsearch/elasticsearch-analysis-kuromoji/2.4.0
2.設定
CentOSではインストール直後は以下のディレクトリ構成となりました。
/etc/elasticsearch/ ・・・設定ファイルなど
/usr/share/elasticsearch/ ・・・実行ファイルやプラグインなど
設定ファイルは/etc/elasticsearch/elasticsearch.ymlなので、各ノードのファイルを編集していきます。
・IP:192.168.33.21での設定
ノードの名前を”apple”としてみました。また、shardは全部で3、今回はレプリケーションを行わない設定とします。そして連携するサーバー群(elasticsearchの用語ではclusterと言う)にも名前を付けて”tac”としておきます。
clusterの属するサーバーをお互いが見つける仕組みはdiscoveryで指定します。今回はunicastによるdiscoveryを指定しました。
cluster.name: tac node.name: "apple" index.number_of_shards: 3 index.number_of_replicas: 0 network.host: 192.168.33.21 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
・IP:192.168.33.22での設定
ノードの名前を”banana”とし、データノードとして設定します。
cluster.name: tac node.name: "banana" node.master: false node.data: true network.host: 192.168.33.22 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
・IP:192.168.33.23での設定
こちらはノードの名前を”cinamon”とし、bananaノード同様データノードとして設定します。
node.name: "cinamon" node.master: false node.data: true network.host: 192.168.33.23 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
ここまで設定できたら、各サーバーのelasticsearchを再起動します。
service elasticsearch restart
appleノードのサーバで以下のコマンドを実行し、設定が正しく行われているかを確認します。
curl 192.168.33.21:9200/_cluster/health?pretty
結果は以下のようになりました。
{
"cluster_name" : "tac",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0
}
elasticsearchはデータの作成や更新、削除、サーバーへの各種実行など、すべてRestFullなリクエストによって行い、データのやり取りはJSONが用いられます。
上記結果ではstatusがgreenとなっていればOKです。yellowとなっている場合は、shardやreplicaの数の設定が間違っている可能性があります。number_of_nodes、number_of_data_nodes、active_primary_shardsとactive_shardsが3となっており、正しく設定が反映されていますね。
今回の実験では、設定は以上となります。
3.スキーマの登録とデータの作成
elasticsearchはRDBと異なり、スキーマレスなデータを扱うことができます。今回は各ノードに対して自動的にドキュメントが分散配置されることを確認したいので、データ構造を指定せずにデータを入れる箱だけ用意します。
以下のコマンドを実行すると、shopという名前のインデックス(RDBではテーブルに相当する)が作成されます。
curl -XPOST '192.168.33.21:9200/shop'
では、実際に適当なデータをshopインデックスに登録してみます。データの登録は以下のコマンドを実行します。
※今回はデータ登録に関するコマンドの説明は割愛します。
curl -XPUT http://192.168.33.21:9200/shop/main/1 -d '{"title" : "This is the first document."}'
curl -XPUT http://192.168.33.21:9200/shop/main/2 -d '{"title" : "This is the second document."}'
curl -XPUT http://192.168.33.21:9200/shop/main/3 -d '{"title" : "This is the third document."}'
登録したデータを確認するには、次のコマンドを実施します。
curl -XGET http://192.168.33.21:9200/shop/main/1
すると以下のJSONが返されます。
{"_index":"shop","_type":"main","_id":"1","_version":1,"found":true,"_source":{"title":"This is the first document."}}
各ノードに対して、登録したドキュメントが分散配置されているでしょうか?headプラグインを用いて確認してみましょう。
Webブラウザを立ち上げて、http://192.168.33.21:9200/_plugin/head/にアクセスすると、現在のcluster情報が表示されます。
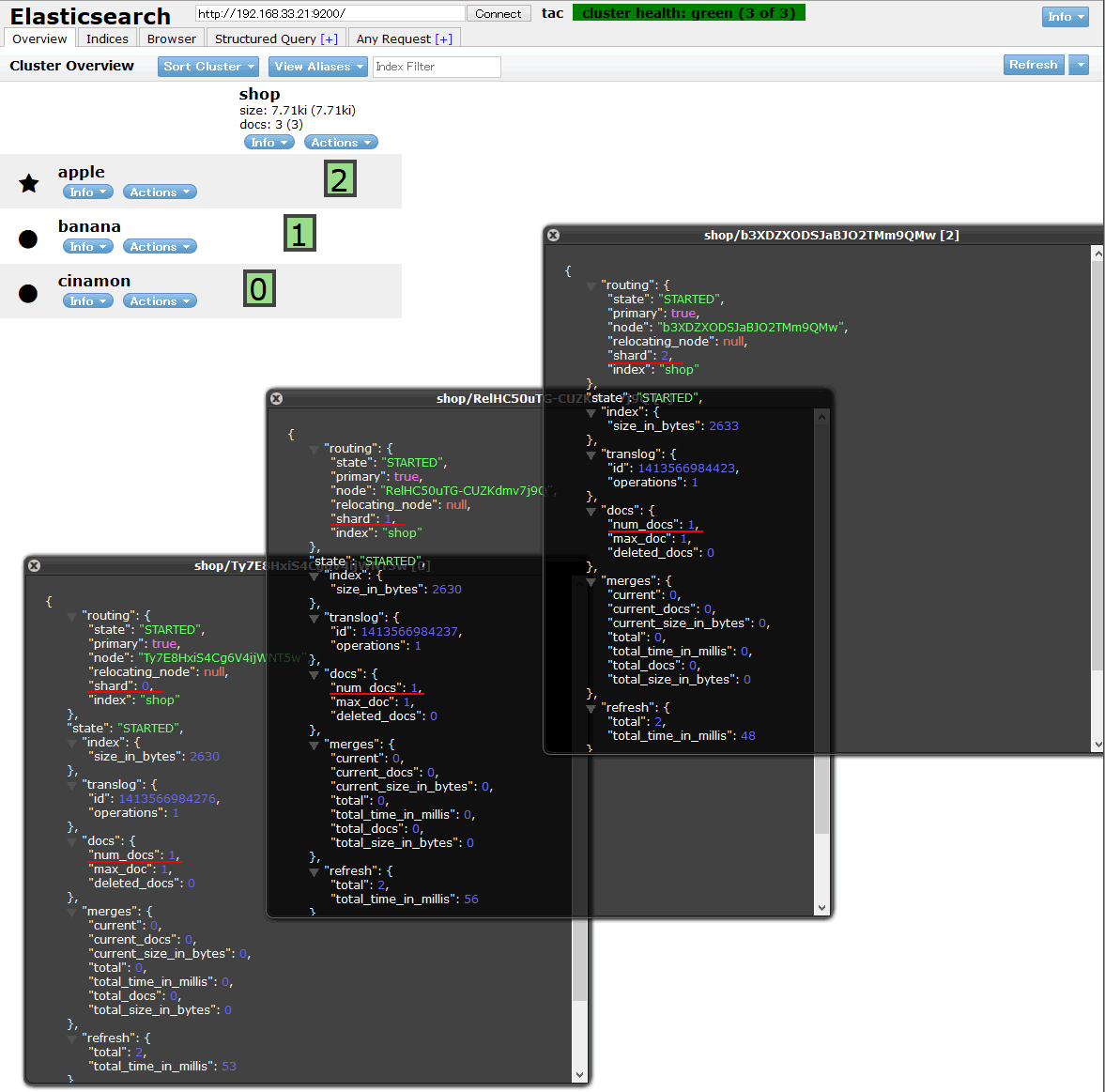
apple、banana、cinamonノード(サーバー)が表示され、緑の四角がshardを表しています。
設定でnumber_of_shardsを3にしたので、合計3つのシャードが自動的に各ノードに割り振られました。
shardを表す四角をクリックして各shardの詳細を表示したのが上の画像です。
各shardのnum_docsが1になっており、登録した3件の文書が各shardに1件ずつ割り振られた状態となっています。
データの登録も読み込みも、マスターノードに対してリクエストを投げれば、あとは勝手にうまい具合に処理されることが確認できました。
以上、elasticsearchのインストールから、複数ノードを使ったclusterの構築でした。