Linuxサーバーでディスク容量が逼迫し始めたとき、どのディレクトリが容量を食ってるか調査する手段。
しょっちゅう使う事がないので、いざというときに忘れているから覚え書きとして...。
#du -h –max-depth=1 /
とすると、ルートディレクトリ配下のディレクトリ毎にどれだけ容量を食ってるかが表示される。
#du -h –max-depth=1 /var
とかで下層を掘っていくことが可能。
Linuxサーバーでディスク容量が逼迫し始めたとき、どのディレクトリが容量を食ってるか調査する手段。
しょっちゅう使う事がないので、いざというときに忘れているから覚え書きとして...。
#du -h –max-depth=1 /
とすると、ルートディレクトリ配下のディレクトリ毎にどれだけ容量を食ってるかが表示される。
#du -h –max-depth=1 /var
とかで下層を掘っていくことが可能。
モッツァレラチーズ作りに挑戦です!

・低温殺菌牛乳・・・2L
・レンネット粉末・・・耳かき1杯程度の粉末を10ccの水に溶かしておく
・クエン酸粉末・・・小さじ1を20ccの水に溶かしておく
牛乳を鍋で12℃まで最弱火で加熱したあと、クエン酸水を入れてゆっくりと混ぜ5分ほど待ちます。
牛乳に少しモロモロっとした塊ができ始めるので、最弱火で7分くらいかけて32℃まで温めます。
牛乳があったまったらレンネット水をいれて混ぜ、また5分程度待ちます。
この時に徐々に牛乳が固まり始めます。
牛乳を45℃まで最弱火で加熱します。この時、事前に固まった牛乳(カード)をナイフやスケッパーでサイの目状に切っておきます。
...って、あれ?あんまり固まってないぞ?

カードを鍋からお玉などですくい、キッチンペーパーなどで水切りします
鍋に残ったホエーを85℃まで加熱します。
加熱したホエーに水切りしたカードをお玉ですくって入れ、耐熱手袋を手にはめてアツアツのカードをこねます...こねます...
なんだこれ、ボソボソすぎてこねるどころじゃねぇ...砂場の砂握ってるみたいで、指の間から全部こぼれていくし...。
数回こねたら伸びとツヤが出てくるらしいが...いつまでたってもコナゴナのカードが指の間から出ていくばかり!
こねてまとまったら、濃い塩水に1時間程度つけて完成!
できたー!おいしいカッテージチーズですよ!

え、モッツァレラチーズ?なにそれ?
ウワーン、また再チャレンジしてやるー!
おそらく、クエン酸の量が多かったのではないかと思います。
2番の手順であまり固まっていなかったため、参考レシピの指示に従いクエン酸を追加したのですが、その時の分量が多かったため急速に水分が分離してしまい、レンネットによる凝固がうまくいかなかったような気がしています。
もしくはレンネットの量が少なかったか...。
何事も、やってみないと分からないものですね。
次こそは、おいしいモッツアレラチーズができたらいいなぁ!
Kindle Fire端末向けにPushを組み込もうとしてADMを実装していましたが、Amazonのマニュアルに従いassetsフォルダにapi_key.txtを作り、いざ実機で動作確認しようとしたところ、
E/ADM: ADM Error INVALID_SENDER – Unable to parse API Key for package [package_name]. Did you forget to embed it?
(お前、api_keyファイル埋め込んでなくね?)
って言われて、登録IDすらろくに取得できずに数時間無駄にしました。
ちなみに環境はWindows10上でAndroidStudio2.xを使っての開発です。
以下、原因と修正内容です。
原因:SecurityProfileのSignatureに入力するMD5が、本番リリース用のKeyStoreFileから取得したMD5だった
そもそもですね、恥ずかしながらKeyStoreファイルなんて自分が用意したものしか知らなかったので、それのMD5が必要なんだとばかり思っていたら、USBデバッグとかでは自動的に用意されたKeyStoreファイルが使われてるんですね。知りませんでした。
修正:debug.keystoreからMD5を取得する
ちなみにうちの環境では「C:\Users\[ユーザー]\.android\debug.keystore」に存在していました。これをkeytoolにかけてMD5を取得し、SecurityProfileに登録してAPI keyを取得するとうまくいきました!
keytoolで指定するaliasは「androiddebugkey」。なのでコマンドラインはこんな感じです。
keytool -list -v -alias androiddebugkey -keystore C:\Users\[ユーザー]\.android\debug.keystore
表題の通り、Vagrantの仮想環境を別PCに移行するため、移行元にてvagrant package してできたboxファイルを、移行先PCでvagrant add したあと仮想環境を起動すると、見事にeth1、eth2あたりがなくなっていて、ホストPCから仮想サーバーにアクセスできない状態でした。(vagrant sshは使えた)
移行元と移行先で、ネットワークアダプタに割り当てられるMacアドレスが変わるために仮想環境側ではネットワークアダプタが見つからなくなるようで、以下の通り仮想環境側のファイルを削除した後、vagrant hult -> vagrant up で起動するとネットワークアダプタが復活しました。
rm /etc/udev/rules.d/70-persistent-net.rules
rm /etc/sysconfig/network-scripting/ifcfg-eth1
こちらを参考にさせていただきました。
http://d.hatena.ne.jp/nagachika/20140121/vagrant_box_with_centos64
というか、そのままですね…。
全文検索したいよね。
でも、100万件とかのデータに対してRDBで「like ‘%xxxx%’」とかしたくないよね。
ということで、全文検索エンジンの登場です。
全文検索エンジンは古くからいろいろありますが、elasticsearchの特徴はその名の通りelasticにスケールアウトが簡単なとこでしょうか。
他の全文検索エンジンで有名なところだとSolrやGroongaなんかもありますが、スケールアウトの面ではelasticsearchが秀でているようです。(僕自身は他のを試したことが無いので詳細は不明ですが…)
CentOS6.3で試しています。
elasticsearchはJavaで出来ているので、jdをインストールします。
yum install java-1.7.0-openjdk-devel
次にelasticsearchのリポジトリを追加します。
vi /etc/yum.repos.d/elasticsearch.repo
で、以下の内容をコピペ。(elasticsearch1.4.xを対象としています)
[elasticsearch-1.4] name=Elasticsearch repository for 1.4.x packages baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
んでもって、yumでインストール。
yum install elasticsearch
1つのノードだけでよければ、elasticsearchのインストールは以上で完了です。
今回は複数ノードを用意して、ドキュメントが各ノードに分散されることを確認したかったので、同じ作業を3台のサーバーに対して行いました。
(実際は勉強用の環境なので、Vagrant+Chefでサクッと3台立ち上げてprovisionしただけですが…)
で、各サーバーは以下のようになりました。
・IP:192.168.33.21(Master & Data ノード)
・IP:192.168.33.22(Data ノード)
・IP:192.168.33.23(Data ノード)
IP192.168.33.21はマスターとして各ノードを管理し、また自ノードでもデータを保持します。
それ以外はマスターに管理される状態で、データだけを保持するノードとする予定ですが、マスターやデータノードの設定は次になります。
今後の作業のために、headプラグインとkuromojiプラグインをインストールしておきます。
headプラグインはクラスターやノード、インデックスの状態を確認するためのプラグイン。なので、マスターにする192.168.33.21にのみインストールしました。
/usr/share/elasticsearch/bin/plugin -install mobz/elasticsearch-head
kuromojiは日本語の形態素解析用プラグインです。
今回の実験では使いませんが、日本語の全文検索ではほぼ必須となるでしょう。
/usr/share/elasticsearch/bin/plugin -install elasticsearch/elasticsearch-analysis-kuromoji/2.4.0
CentOSではインストール直後は以下のディレクトリ構成となりました。
/etc/elasticsearch/ ・・・設定ファイルなど
/usr/share/elasticsearch/ ・・・実行ファイルやプラグインなど
設定ファイルは/etc/elasticsearch/elasticsearch.ymlなので、各ノードのファイルを編集していきます。
ノードの名前を”apple”としてみました。また、shardは全部で3、今回はレプリケーションを行わない設定とします。そして連携するサーバー群(elasticsearchの用語ではclusterと言う)にも名前を付けて”tac”としておきます。
clusterの属するサーバーをお互いが見つける仕組みはdiscoveryで指定します。今回はunicastによるdiscoveryを指定しました。
cluster.name: tac node.name: "apple" index.number_of_shards: 3 index.number_of_replicas: 0 network.host: 192.168.33.21 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
ノードの名前を”banana”とし、データノードとして設定します。
cluster.name: tac node.name: "banana" node.master: false node.data: true network.host: 192.168.33.22 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
こちらはノードの名前を”cinamon”とし、bananaノード同様データノードとして設定します。
node.name: "cinamon" node.master: false node.data: true network.host: 192.168.33.23 discovery.zen.ping.multicast.enabled: false #コメントアウトを外す discovery.zen.ping.unicast.hosts: ["192.168.33.21"] #コメントアウトを外してマスターノードのIPを指定
ここまで設定できたら、各サーバーのelasticsearchを再起動します。
service elasticsearch restart
appleノードのサーバで以下のコマンドを実行し、設定が正しく行われているかを確認します。
curl 192.168.33.21:9200/_cluster/health?pretty
結果は以下のようになりました。
{
"cluster_name" : "tac",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0
}
elasticsearchはデータの作成や更新、削除、サーバーへの各種実行など、すべてRestFullなリクエストによって行い、データのやり取りはJSONが用いられます。
上記結果ではstatusがgreenとなっていればOKです。yellowとなっている場合は、shardやreplicaの数の設定が間違っている可能性があります。number_of_nodes、number_of_data_nodes、active_primary_shardsとactive_shardsが3となっており、正しく設定が反映されていますね。
今回の実験では、設定は以上となります。
elasticsearchはRDBと異なり、スキーマレスなデータを扱うことができます。今回は各ノードに対して自動的にドキュメントが分散配置されることを確認したいので、データ構造を指定せずにデータを入れる箱だけ用意します。
以下のコマンドを実行すると、shopという名前のインデックス(RDBではテーブルに相当する)が作成されます。
curl -XPOST '192.168.33.21:9200/shop'
では、実際に適当なデータをshopインデックスに登録してみます。データの登録は以下のコマンドを実行します。
※今回はデータ登録に関するコマンドの説明は割愛します。
curl -XPUT http://192.168.33.21:9200/shop/main/1 -d '{"title" : "This is the first document."}'
curl -XPUT http://192.168.33.21:9200/shop/main/2 -d '{"title" : "This is the second document."}'
curl -XPUT http://192.168.33.21:9200/shop/main/3 -d '{"title" : "This is the third document."}'
登録したデータを確認するには、次のコマンドを実施します。
curl -XGET http://192.168.33.21:9200/shop/main/1
すると以下のJSONが返されます。
{"_index":"shop","_type":"main","_id":"1","_version":1,"found":true,"_source":{"title":"This is the first document."}}
各ノードに対して、登録したドキュメントが分散配置されているでしょうか?headプラグインを用いて確認してみましょう。
Webブラウザを立ち上げて、http://192.168.33.21:9200/_plugin/head/にアクセスすると、現在のcluster情報が表示されます。
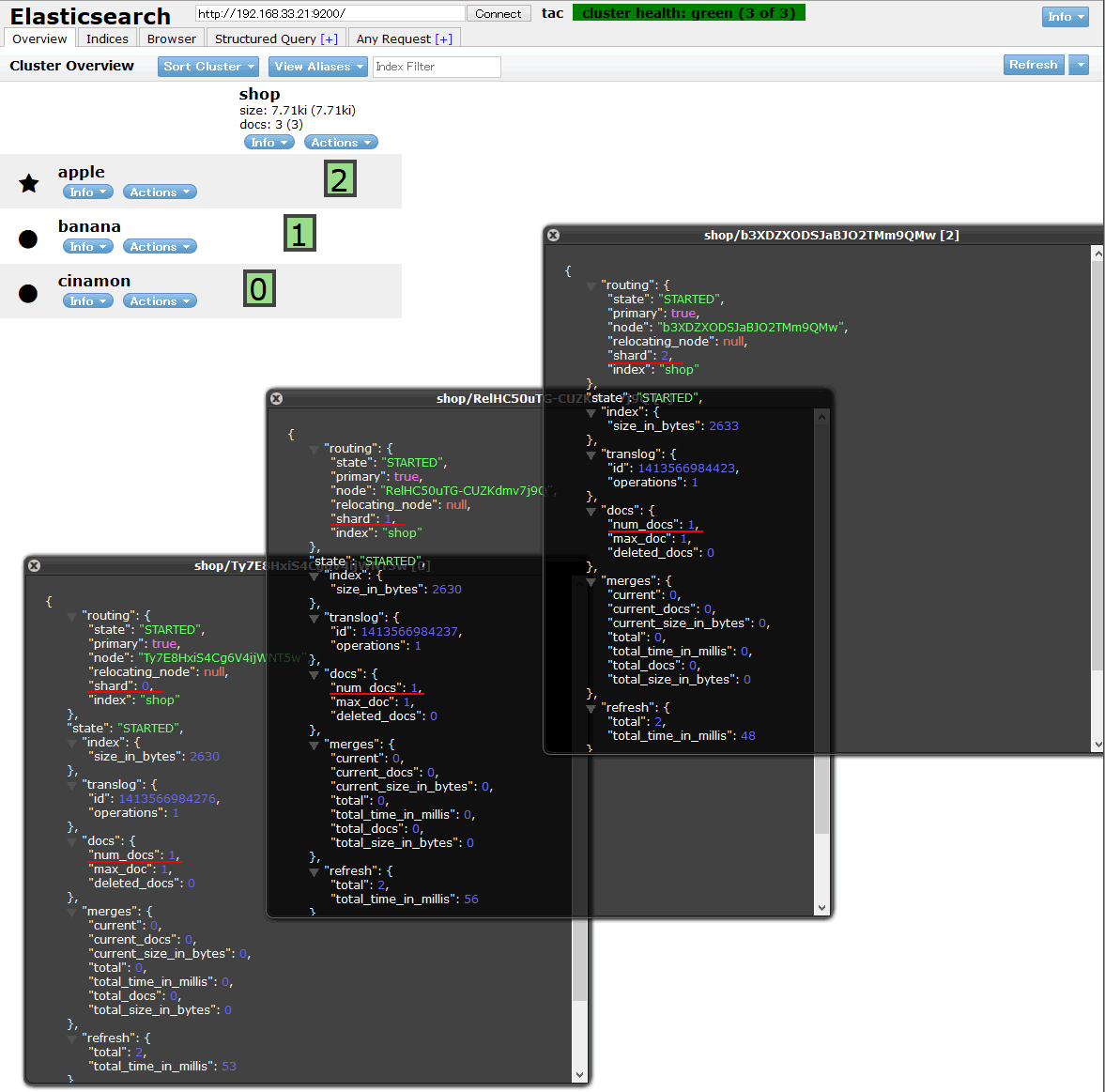
apple、banana、cinamonノード(サーバー)が表示され、緑の四角がshardを表しています。
設定でnumber_of_shardsを3にしたので、合計3つのシャードが自動的に各ノードに割り振られました。
shardを表す四角をクリックして各shardの詳細を表示したのが上の画像です。
各shardのnum_docsが1になっており、登録した3件の文書が各shardに1件ずつ割り振られた状態となっています。
データの登録も読み込みも、マスターノードに対してリクエストを投げれば、あとは勝手にうまい具合に処理されることが確認できました。
以上、elasticsearchのインストールから、複数ノードを使ったclusterの構築でした。
開発マシンを新しくし、今までのようにVirtualBoxとVagrant、chefをインストールしてvagrant upしたら…
[default] Waiting for VM to boot. This can take a few minutes.と表示されたまま一向に進まず、そのままssh接続でタイムアウトしてしまいchefが全く実行されない現象にあたりました。
いろいろネットを見て回るとVirtualBoxのGuiモードで起動するとヒントがあるかも、ということでVagantfileを見ると次のようなオプションがコメントアウト状態になってるので、コメントを外してGuiモードを有効にします。
vb.gui = true
この状態でvagrant upするとVirtualBoxのGui画面が立ち上がり、Linuxの起動画面が表示されます。
で、しばらく様子を見ているとOSが立ち上がった後にLogin画面になるのですが、突如VirtualBoxのエラーダイアログが表示されました。
仮想化支援機構(VT-x/AMD-V)を有効化できません。64ビットゲストOSは64ビットCPUを検出できず、起動できません。
ホストマシンのBIOS設定でVT-x/AMD-V を有効化してください。
「ハァ?僕、小学校でそんなの習ってません!」
どうやらBIOSから「Intel(R) virtualization technology」をenabledにしないとダメならしく、BIOSの設定を変更するとすんなり起動してchefが動きました。
以前のマシンではこんな設定変更したことなかったので、vagrant upができずに焦りまくり。
ブログに書いた内容は大したことないのですが、原因究明するまですごい時間を無駄にしてしまいました…。
急遽OCRを利用する必要があったので、フリーのライブラリを探してみた。 Linux(CentOS)で使えるものが無いか物色する中で、GoogleがOSSとして提供しているライブラリTesseractがあったので、導入から使用方法までを簡単に書いてみる。
バイナリでも落ちているようだけど、ひとまずソースをダウンロードしてコンパイル、インストールすることにした。
デフォルトのCentOSでは入っていないパッケージをインストールする必要がある。
yum install libpng-devel libjpeg-devel libtiff-devel zlib-devel giflib-devel autoconf automake
Tesseractは内部でleptonicaを呼び出しているようなので、こちらを先にインストールする必要がある。
wget http://www.leptonica.com/source/leptonica-1.69.tar.gz tar -xvzf leptonica-1.69.tar.gz cd leptonica-1.69 ./configure make make install
いよいよtesseract本体のインストール。 OCRで解析させたい言語ごとに解析用ファイルをダウンロードしておく必要がある。今回は英語と日本語を使う事にした。 この手順でインストールすると、tesseract本体は/usr/local/share/にインストールされるので、言語ごとの対応ファイルは解凍後、/usr/local/share/tessdataに移動させる。
wget http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.02.tar.gz wget http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.eng.tar.gz wget http://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.jpn.tar.gz tar zxf tesseract-ocr-3.02.02.tar.gz cd tesseract-ocr ./autogen.sh ./configure make make install cd ../ tar -xvzf tesseract-ocr-3.02.eng.tar.gz mv ./tesseract-ocr/tessdata/eng* /usr/local/share/tessdata/ tar -xvzf tesseract-ocr-3.02.jpn.tar.gz mv ./tesseract-ocr/tessdata/jpn* /usr/local/share/tessdata/
これでインストールは完了。
下記のようにコマンドを叩けば画像ファイル[hogehoge.gif]を解析してfugafuga.txtに、テキストファイルとして結果を吐き出す。
tesseract hogehoge.gif fugafuga
このままでは、日本語はおろか英語であっても惨憺たるありさまなので、何とか精度向上を図る。
せっかくダウンロードしてきて展開した辞書ファイルがあるので、それで何とかなる内容なら積極的につかっていきましょう。 例えば日本語の辞書ファイルを指定する方法は以下の通り。
tesseract hogehoge.gif fugafuga -l jpn
また、使用されている文字が限定的な場合は、設定ファイルを用意することで精度を向上させることが可能です。 1とlをよく間違って解析したりするのですが、例えば数字が絶対含まれず、アルファベットのみ使用されている画像を解析するのであれば、下記内容の設定ファイルを作成することで誤解析を減らすことが可能です。
tessedit_char_whitelist abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
上記の設定ファイルを読み込ませるには下記のように指定します。
tesseract hogehoge.gif fugafuga alpha.txt
解析する画像の文字が小さいと精度が出ません。いろいろ拡大して、精度の出るサイズになるよう調整してみてください。
アンチエイリアスなどでエッジがぼやけている画像では精度が出ません。なので画像を二値化(白と黒にくっきり分ける)することで精度の向上が期待できます。
http://magiccastanets.blogspot.jp/2012/06/google-tesseract-ocr-os-centos6.html http://www.slideshare.net/takmin/tesseract-ocr WEB-DB-PRESS-Vol-76
http://qiita.com/hatahata/items/4daddebb5e84ea575332
RubyでできてるChefはえらいイケメンならしく、巷でモテモテならしいです。
勉強会とかでも話題に上ることが多く、エロいChefに見られてる気がしたので重い腰を上げて取り掛かってみました。
ザックリまとめると「サーバの状態を保持するツール」ですが、「同じ規格の開発環境を何個も用意したり、配布できるツール」といった使い方も可能で、私としては後者の用途に非常に興味があるわけです。
開発環境を乱立するにあたって、手っ取り早くもめんどくさいXamppとかより「Chefでレシピ用意して立てた方がいいよね!」ってのが、最近の流れかと。
本番環境の運用ではなく、あくまで開発環境の高速乱立(?)を目指すので、ここではChef soloを使っていきたいと思います。
上記の準備が出来たら、Vagrantを使ってVirturalBoxの仮想サーバを作成→起動→停止を行ってみます。
まずは仮想サーバの入手からですが、下記URLで好みの環境を選びます。
http://www.vagrantbox.es/
2013/06/03時点では、各サーバのURLの手前に「Copy」と表示されているので、それをクリックすればクリップボードにURLがコピーされます。
コンソール(コマンドプロンプト)等を開いて、以下のコマンドを実行。
#仮想環境の/Vagrantディレクトリと同期されるホスト側フォルダを作成して移動 mkdir c:\project cd c:\project #仮想環境追加 vagrant box add [title] [virtual machine image url] #仮想環境にcentosという名前を付け、CentOS6.3 64bitのサーバを作成する場合の例 vagrant box add centos https://dl.dropbox.com/u/7225008/Vagrant/CentOS-6.3-x86_64-minimal.box #仮想環境の設定ファイルを自動作成 vagrant init centos #仮想環境を起動! vagrant up
これで仮想環境が起動します。
ここまで確認したら、
vagrant halt
で、一旦仮想環境を停止しておきます。
先ほどvagrant upを実行したフォルダにはVagrantfileが出来上がっています。
仮想マシンの動作環境などを事細かく記載する設定ファイルですが、ここでIPを指定して起動するよう変更しておきます。
#下記行のコメントを外す config.vm.network :private_network, ip: "192.168.33.10"
まずはChefによる連携等を行うだけであれば、これだけの設定でOKでしょう。
コマンドプロンプトからvagrant upで再度、仮想環境を起動します。
Chefの世界ではリポジトリとかキッチンとか呼ばれるものを作成します。
コマンドプロンプトで、作成したprojectフォルダに移動し、knife soloを実行します。
knife solo prepare vagrant@192.168.33.10
パスワードを求められればvagrantでOKです。
Cygwinを入れてる環境では以下のようなエラーが発生するかもしれません。
Bootstrapping Chef... ERROR: ArgumentError: non-absolute home (ArgumentError)
その場合は、下記のようにHOMEを空にするとうまく行くと思います。
たんめん日記さんの記事を参考にしました。
set HOME=
projectフォルダ内にて狂ったようにナイフを振るいます。
なぜ、キッチンでナイフを振り回したらレシピが作られるのか、風景を想像するとかなり謎ですが細かいことは気にせずコマンドを打つべし。
#cookbooksフォルダにcookbookを作成 knife cookbook create myrecipe -o cookbooks
これでc:\project\chef-repo\cookbooks\myrecipe\recipes\default.rbというレシピファイルができるはずです。
このファイルに、Chefに実行させたい内容を書いていく事になります。
出来上がった上記レシピに実際に処理を書いてみます。
いきなりですが、httpサーバをインストールさせたいと思います。
下記の内容をc:\project\chef-repo\cookbooks\myrecipe\recipes\default.rbに追記します。
package "httpd" do
action :install
end
このままでは、まだChefは作ったレシピを読めません。nodeのjsonファイルとVagrantfileを変更して、Chefがmyrecipeを読み込むよう設定します。
まずはVagrantfile。
config.vm.provision :chef_solo do |chef|
# cookbookのありか。Vagrantfileからの相対パス
chef.cookbooks_path = "./chef-repo/cookbooks"
# 使用するrecipeの名前
chef.add_recipe "myrecipe"
end
次にc:\project\chef-repo\nodes\192.168.33.10.jsonを編集。
{"run_list":[" recipe [ myrecipe ]"]}
ここまでくれば、あとは仮想環境を再起動してやればChefがレシピに従って、httpdをインストールしてくれます。
#仮想環境の停止 vagrant halt #仮想環境の起動 vagrant up Bringing machine 'default' up with 'virtualbox' provider... [default] Setting the name of the VM... [default] Clearing any previously set forwarded ports... [default] Creating shared folders metadata... [default] Clearing any previously set network interfaces... [default] Preparing network interfaces based on configuration... [default] Forwarding ports... [default] -- 22 => 2222 (adapter 1) [default] Booting VM... [default] Waiting for VM to boot. This can take a few minutes. [default] VM booted and ready for use! [default] Configuring and enabling network interfaces... [default] Mounting shared folders... [default] -- /vagrant [default] -- /tmp/vagrant-chef-1/chef-solo-1/cookbooks [default] Running provisioner: chef_solo... Generating chef JSON and uploading... Running chef-solo... [2013-06-08T17:20:06+00:00] INFO: *** Chef 11.4.4 *** [2013-06-08T17:20:06+00:00] INFO: Setting the run_list to ["recipe[myrecipe]"] from JSON [2013-06-08T17:20:06+00:00] INFO: Run List is [recipe[myrecipe]] [2013-06-08T17:20:06+00:00] INFO: Run List expands to [myrecipe] [2013-06-08T17:20:06+00:00] INFO: Starting Chef Run for localhost [2013-06-08T17:20:06+00:00] INFO: Running start handlers [2013-06-08T17:20:06+00:00] INFO: Start handlers complete. [2013-06-08T17:20:06+00:00] INFO: Processing package[httpd] action install (myrecipe::default line 9) [2013-06-08T17:20:26+00:00] INFO: package[httpd] installing httpd-2.2.15-28.el6.centos from updates repository [2013-06-08T17:20:36+00:00] INFO: Chef Run complete in 29.548068181 seconds [2013-06-08T17:20:36+00:00] INFO: Running report handlers [2013-06-08T17:20:36+00:00] INFO: Report handlers complete
めでたく、自動でhttpサーバがインストールされました!
レシピはインストールだけでなく、サービス登録やファイル、ディレクトリの作成はもちろん、configファイルの自動設定なども盛り込むことができます。
気が向いたらそれらも記事にします。
参考文献
入門Chef Solo – Infrastructure as Code
Windows7上で Vagrant + Chef solo + knife-soloを使い、Ubuntu + ubuntu-desktopの環境を構築してみた
新しいデバイスが届きました。
ロジクールのタッチパッド「T650」です。
真ん中の正方形の物体がブツです。
今まで使っていたマウスが古くなり、ゴム製の部分が削れて手や設置面が黒く汚れてくるようになったため買い替えを決意しました。
購入に当たり色々検討したのですが、なるべくキーボードから手をはなさずにカーソル操作ができるデバイスということで、このタッチパッドにしました。
ひと昔前のタッチパッドは非常に使い辛いシロモノで、ノートパソコンにオマケでついてくるパッドのイメージしかありませんでしたが。
AppleのMagic Trackpad(マジ虎)以来、タッチパッドが大きく進化したように思います。
WinユーザーとしてはAppleのマジ虎は憧れでしたが、T650でようやくそれに近い操作感のデバイスがWinでも使えるようになりました。
二本指タップで右クリック。
二本指スワイプで上下左右のスクロール。
三本指スワイプでアプリケーションの切り替えや、デスクトップの表示、戻る、進む。
ピンチ操作で画面のズームイン、ズームアウト。
この辺の操作ができることで、従来のタッチパッドとは比べ物にならない用な操作性を得ることができるようになっています。
もちろん、使い慣れたマウスの方がしっくり来るし、細かい操作はマウスに軍配が上がる気もしますが、私にとっては十分使えるデバイスのようです。
何より、キーボードの手前に配置することで、マウスに握り変えることなくカーソル操作ができるのがとても素晴らしい点です。
また、写真の通りキーボードアームと併用することで、常に手の位置を膝上付近から離す事なくすべての作業を完結できることで、肩の疲れ方がかなり緩和されることが期待されます。
この辺、気になる方は「膝上キーボード」でググってみてください。
オープンソース系のコードを眺めているとたまに目にする「i18n」の文字。
国際化が行われているソフトウェアでよく出てくるのですが、翻訳関係のファイルを扱う関数やライブラリなんかにこの文字が冠せられてたりします。
最初はあまり気にも留めなかったのですが、ふとしたきっかけで知った「i18n」の意味は「internationalizationの略」というもの。
最初のiと、最後のnの間に18文字あるから「i18n」…なんて雑な略し方なんだよ。
でも、この略し方だと相当長いのでもOKですよね。
例えばタイの首都、バンコクの正式名称。
英語表記だと「Krungthepmahanakhon Amonrattanakosin Mahintharayutthaya Mahadilokphop Noppharatratchathaniburirom Udomratchaniwetmahasathan Amonphimanawatansathit Sakkathatiyawitsanukamprasit」なので、途中のスペースを削ると全部で212文字。
…ということは「k210t」でOK!
いやー、タイの人に怒られそうだわ。